Opencv图像处理应用 —— 一个场景下的手写汉字定位优化
手写文字检测方法有很多,传统图像算法,深度学习方法等。我遇到一个简单的场景是类似下面这种方格中的手写字定位,然后进行后续工作。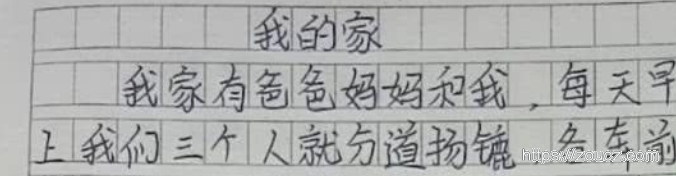
需求特点是:1.场景简单 2.需要定位出单个文字文字,以裁剪出单个文字做后续操作。这种场景用opencv的mser算法就可以了。
实践的过程中的一些小点,在这里记录一下吧,方便后面回忆。
opencv mser 轮廓检测,找出边框
关键步骤:
初始化mser算法,参数不列举了,可查文档
self._mser = cv2.MSER_create(_delta=4, _min_area=120,_max_area=1000, _max_variation=0.8,_edge_blur_size= 0)
检测轮廓,并根据轮廓获取边框,去掉长宽比不合理的框
def _runmser(self, gray, vis, img):
# 获取文本区域
regions, _ = self._mser.detectRegions(gray)
boxes = []
# 取轮廓方框,去掉长宽比过大的框,通过平均像素值去掉空白框
for c in regions:
x, y, w, h = cv2.boundingRect(c)
x1,y1,x2,y2 = [x, y, x + w, y + h]
if w/h>1.5 or h/w > 1.5:
continue
boxes.append([x1,y1,x2,y2])
return boxes

可以看到,边框是有了,但是很多重复的
去除重复框
接上步,思路是去掉重合面积过大的框
# NMS 方法(Non Maximum Suppression,非极大值抑制)
def _nms(self, boxes, overlapThresh):
if len(boxes) == 0:
return []
if boxes.dtype.kind == "i":
boxes = boxes.astype("float")
pick = []
# 取四个坐标数组
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
# 计算面积数组
area = (x2 - x1 + 1) * (y2 - y1 + 1)
# 按得分排序(如没有置信度得分,可按坐标从小到大排序,如右下角坐标)
idxs = np.argsort(y2)
# 开始遍历,并删除重复的框
while len(idxs) > 0:
# 将最右下方的框放入pick数组
last = len(idxs) - 1
i = idxs[last]
pick.append(i)
# 找剩下的其余框中最大坐标和最小坐标
xx1 = np.maximum(x1[i], x1[idxs[:last]])
yy1 = np.maximum(y1[i], y1[idxs[:last]])
xx2 = np.minimum(x2[i], x2[idxs[:last]])
yy2 = np.minimum(y2[i], y2[idxs[:last]])
# 计算重叠面积占对应框的比例,即 IoU
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
overlap = (w * h) / area[idxs[:last]]
# 如果 IoU 大于指定阈值,则删除
idxs = np.delete(idxs, np.concatenate(([last], np.where(overlap > overlapThresh)[0])))
return boxes[pick].astype("int")
效果:
现在定位框看起来好多了,但是不含文字的一些方框也被定位出来了
去掉检测不全的文字
mser算法是组件增加像素阈值,来找出区域,但是汉字由很多偏旁部首组成,部首之间也会有很多空白区域,此时可能部分汉字只框出来了一个部首,上面图中就有一些字只框出来了一部分。
因为后续的步骤中需要完整汉字,如果不全的汉字比较多,就会比较麻烦,需要一些方法减少这种情况。
这里我的思路是,在预处理的时候先对图片做一个开运算,让文字的部首之间糊上一些像素
def _preprocess(self, img):
final = img
# 先开运算(腐蚀再膨胀),让文字部首间联通
kernel = np.ones((5,5), np.uint8)
final = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
# 再灰度
final = cv2.cvtColor(final, cv2.COLOR_BGR2GRAY)
# # 二值化后再用mser算法,效果并不好
# ret, final = cv2.threshold(final,80,255,cv2.THRESH_BINARY)
vis = img.copy()
# cv2.imshow("final", final)
# cv2.waitKey(0)
return final,vis
加上开运算之后:
效果: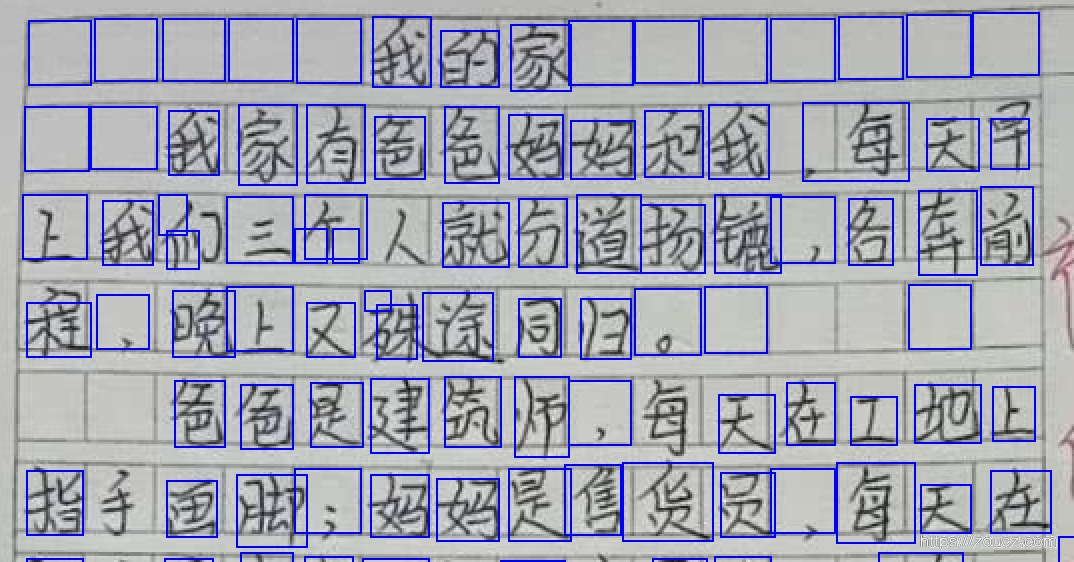
大部分检测不全的框被修复了,但是少量完整框没了, 经过多张测试图对比,整体效果更佳。
去掉背景方框
思路是将定位框缩小,并做一个自适应二值化(排除光线干扰),然后计算其平均像素,如果不含内容,则其像素值应该很高,去掉这种
def _removeWhite(self,gray, boxes, overlapThresh):
keep = []
scale = 0.25
for idx,box in enumerate(boxes):
region =gray[box[1]:box[3], box[0]:box[2]]
# 边缘部分向内部缩进10%,排除作文纸方框边框干扰
height, width = np.shape(region)
if height==0 or width == 0:
continue
region = region[int(scale*height):int((1-scale)*height), int(scale*width):int((1-scale)*width)]
# 普通二值化
# ret,region = cv2.threshold(region,127,255,cv2.THRESH_BINARY)
# 自适应二值化
# region = cv2.adaptiveThreshold(region, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 5, 1)
region = cv2.adaptiveThreshold(region, 255, cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY, 11, 2)
# 计算平均强度,过小则认为其内部无内容,或者是标点,丢弃
avg = cv2.mean(region)[0]
#cv2.waitKey(0)
if avg > overlapThresh:
continue
keep.append(box)
cv2.waitKey(0)
return keep
效果:
这里边有比较多的根据事情情况的算法参数调整,还是挺蛋疼的。
其它
对于更加复杂的场景,这种方法就不适用了,mser算法无法得到文字轮廓,此时可以尝试用深度学习的CTPN网络来做,裁剪出文本行后,再尝试使用传统方法,或者改造网络来获取单个文字的位置。
本文链接:https://www.zoucz.com/blog/2020/05/15/a070a340-9683-11ea-90b5-eb40e9720ed0/
