协程实现原理
1. 程序进程内存布局
本文参考《程序员的自我修养》部分章节的内容,描述了进程虚拟地址空间布局、并调试了函数调用栈帧调度过程。然后基于对函数调用过程的理解,尝试了最简单的协程及协程库的实现方式。最后描述和无栈协程和有栈协程的区别,并列举了常见的无栈协程和它们的实现方式。
1.1 典型虚拟内存布局

上图描述了程序加载执行时,其虚拟内存空间的典型布局,从上到下依次是
- 内核空间
- 自高位地址向低位地址增长的栈空间
- 动态库映射区
- 自低位地址向高位地址生长的堆空间
- 可读写的数据段
- 只读数据段
- 预留区
1.2 多线程的内存空间
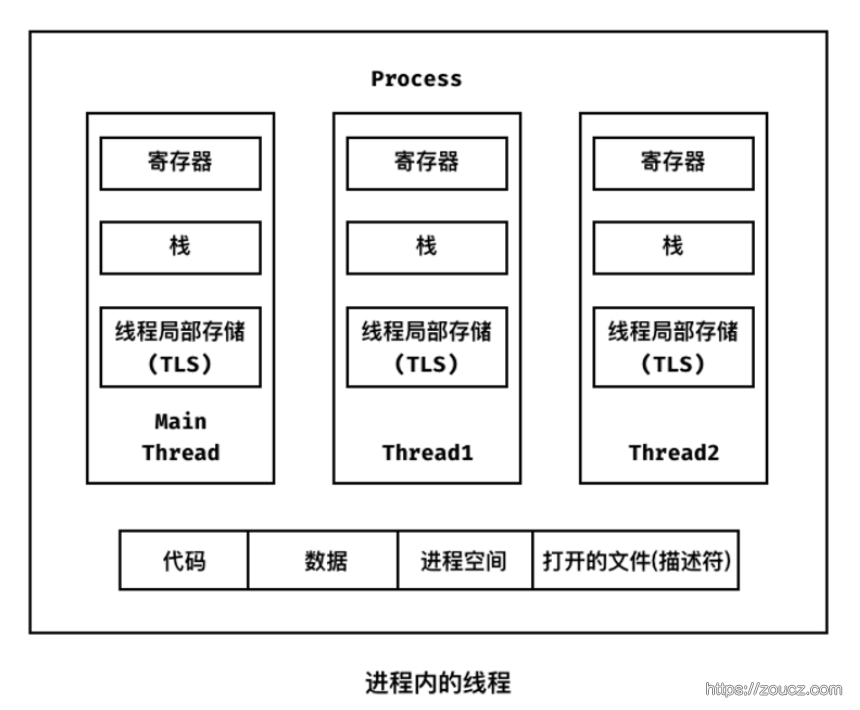
进程内的线程,共享进程的代码、数据、进程空间、打开的fd,但是有各自的寄存器值、栈、线程局部数据。
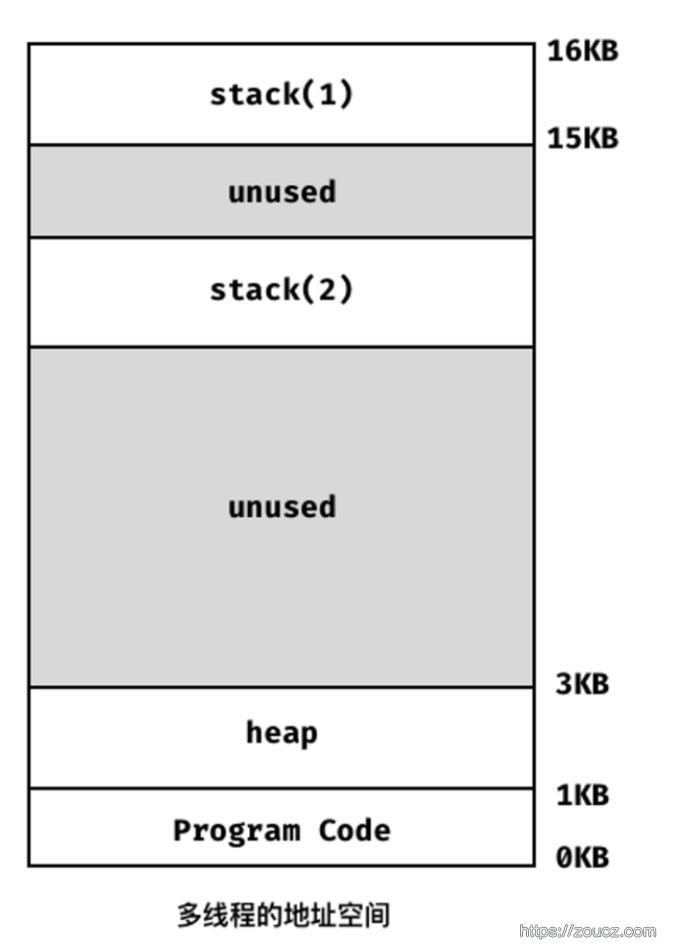
拥有多线程的进程虚拟内存空间中,每个线程都拥有自己的栈。
假设有2个线程运行在一个处理器上,从运行一个线程(T1)切换到另一个线程(T2)时,一定会发生上下文切换。对于进程,我们需要将状态保存到进程控制块(PCB)中,现在我们需要一个或多个线程控制块(TCB)来保存每个线程的状态,但是和进程上下文切换相比,线程在进行上下文切换的时候地址空间保持不变(即不需要切换当前使用的页表)。
1.3 函数执行的栈帧
栈内存中保存了一个函数调用所需要的维护信息,这常常被称为堆栈帧(Stack Frame)或活动记录(Activate Record)。
堆栈帧一般包括如下几方面内容:
- 函数的返回地址和参数
- 临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量
- 保存的上下文:包括在函数调用前后需要保持不变的寄存器
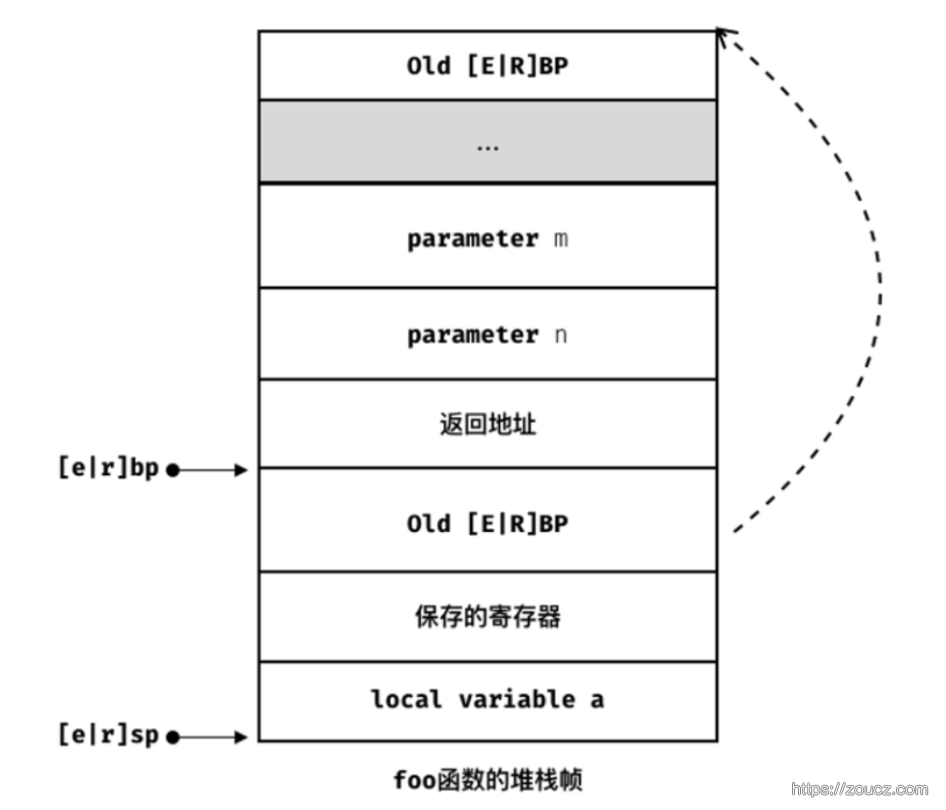
该函数对应的堆栈帧的内存空间如下所示,一个函数的堆栈帧增长过程是这样的:
- 把所有或一部分参数加入栈中,如果有其他参数没有入栈,那么使用某些寄存器传递
- 把当前指令的下一条指令地址压入栈中
- 跳转到函数体执行:
- 把[e|r]bp压入栈中,指向上一个函数堆栈帧中的帧指针的位置(32位的是ebp,64位的是rbp)
- 保存调用前后需要保存不变的寄存器的值
- 将局部变量压入栈中
- …
1.4 函数执行过程调试
寄存器
在x86-64架构的Linux中,常用的寄存器有以下几种:
- 通用寄存器:包括 RAX, RBX, RCX, RDX, RDI, RSI, RBP, RSP, R8-R15。它们主要用于存储临时数据,参与各种算术和逻辑运算。
- 段寄存器:包括 CS, DS, ES, FS, GS, SS。它们主要用于存储内存中各段的基地址。
- 指令指针寄存器:RIP,它存储下一条将要执行的指令的地址。
- 标志寄存器:RFLAGS,它存储了各种状态标志,如零标志(ZF)、进位标志(CF)、奇偶标志(PF)等。
- 浮点寄存器:包括 ST0-ST7,它们用于浮点运算。
- MMX寄存器:包括 MM0-MM7,它们用于多媒体指令集(MMX)的运算。
- XMM寄存器:包括 XMM0-XMM15,它们用于流式 SIMD 扩展指令集(SSE)的运算。
具体的寄存器列表和含义可以参考相关的x86-64架构的相关文档。如Intel官方的《Intel 64 and IA-32 Architectures Software Developer Manuals》或者 https://wiki.osdev.org/CPU_Registers_x86-64 。
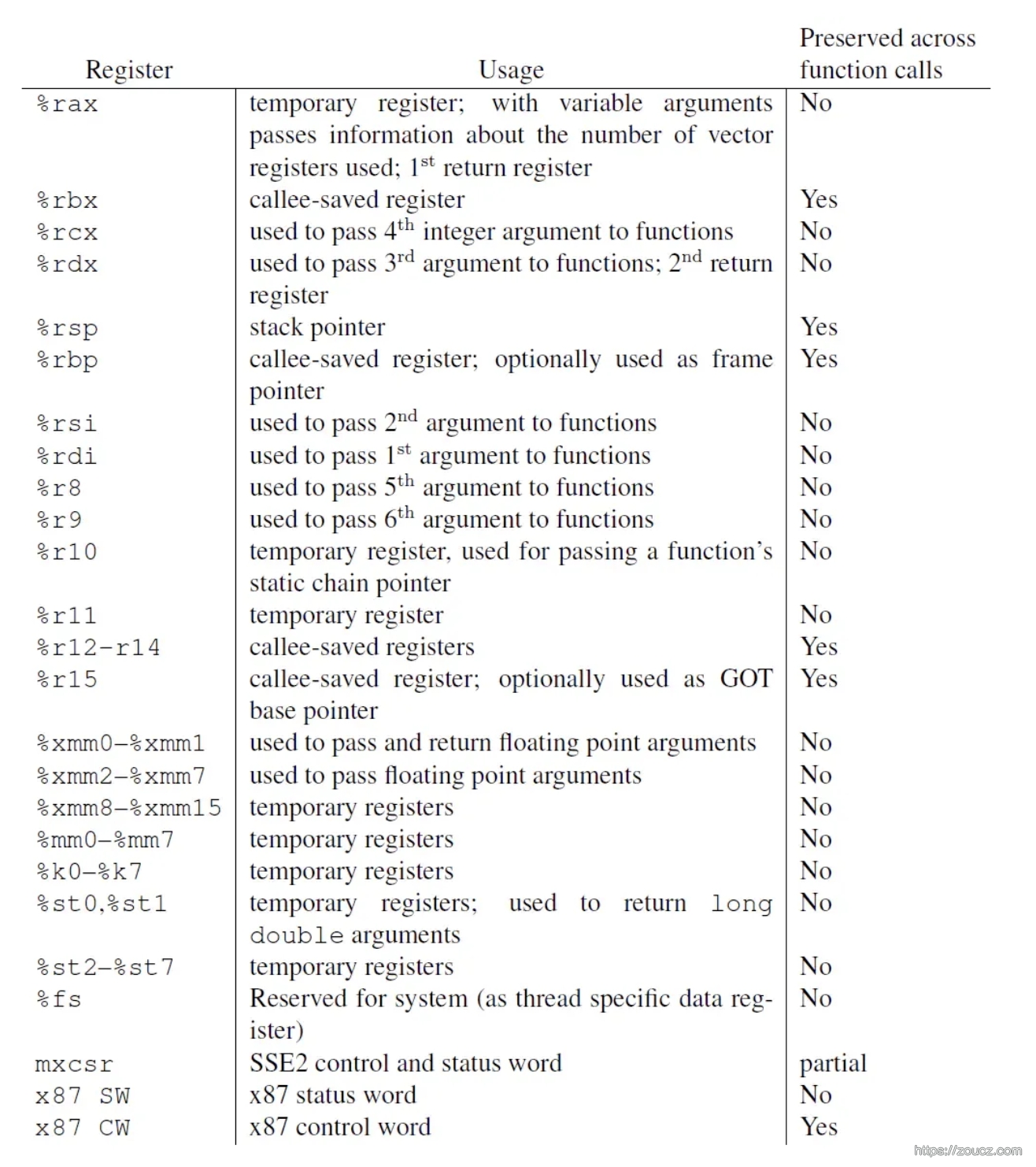
寄存器从易失性(volatility)角度可以分为易失性寄存器和非易失性寄存器。易失性是指在中断、异常、函数调用或上下文切换等情况下,寄存器的值可能会被改变,而且系统不会自动保存和恢复这些值。因此,如果程序需要在这些情况下保留寄存器的值,就需要显式地保存(push)和恢复(pop)这些值。
如上图(System V ABI 规范),下面这些寄存器需要在函数调用过程后,返回原函数时,保证其值与原来一致,即被调函数需要保存其原值,并负责恢复。
- %rbp, %rbx, %r12, %r13, %r14, %r15
- %rsp
- mxcsr
- x87 CW
函数执行过程
下面写一段 c 代码,来逐步执行调试,查看其寄存器操作和栈帧变化情况
1 | int sum(int l, int r) { |
编译出调试版本的可执行文件1
gcc -g ./main.c -o main
基于此可执行文件,我们按下面的计划执行并观察:
- Step1. 观察 main 函数的汇编代码,查看 main 函数自身执行以及调用 sum 函数过程中的操作
- Step2. 观察 sum 函数的汇编代码,查看 sum 函数执行过程中的操作
- Step3. 在 main 函数入口打上断点,查看 main 函数栈帧区间(即 %rbp - %rsp)的值和局部变量值
- Step4. 在调用 sum 函数的地方打上断点,查看 main 函数栈帧区间的值
- Step5. 在 sum 函数入口打上断点,查看 sum 函数的栈帧区间的值、返回地址、%rbp的值指向地址的值
- Step6. 在 main 函数的结尾打上断点,查看 main 函数栈帧区间的值
Step1. 观察 main 函数的汇编代码
然后使用 gdb 进入函数调试,并使用 disassemble 指令反汇编 main 函数
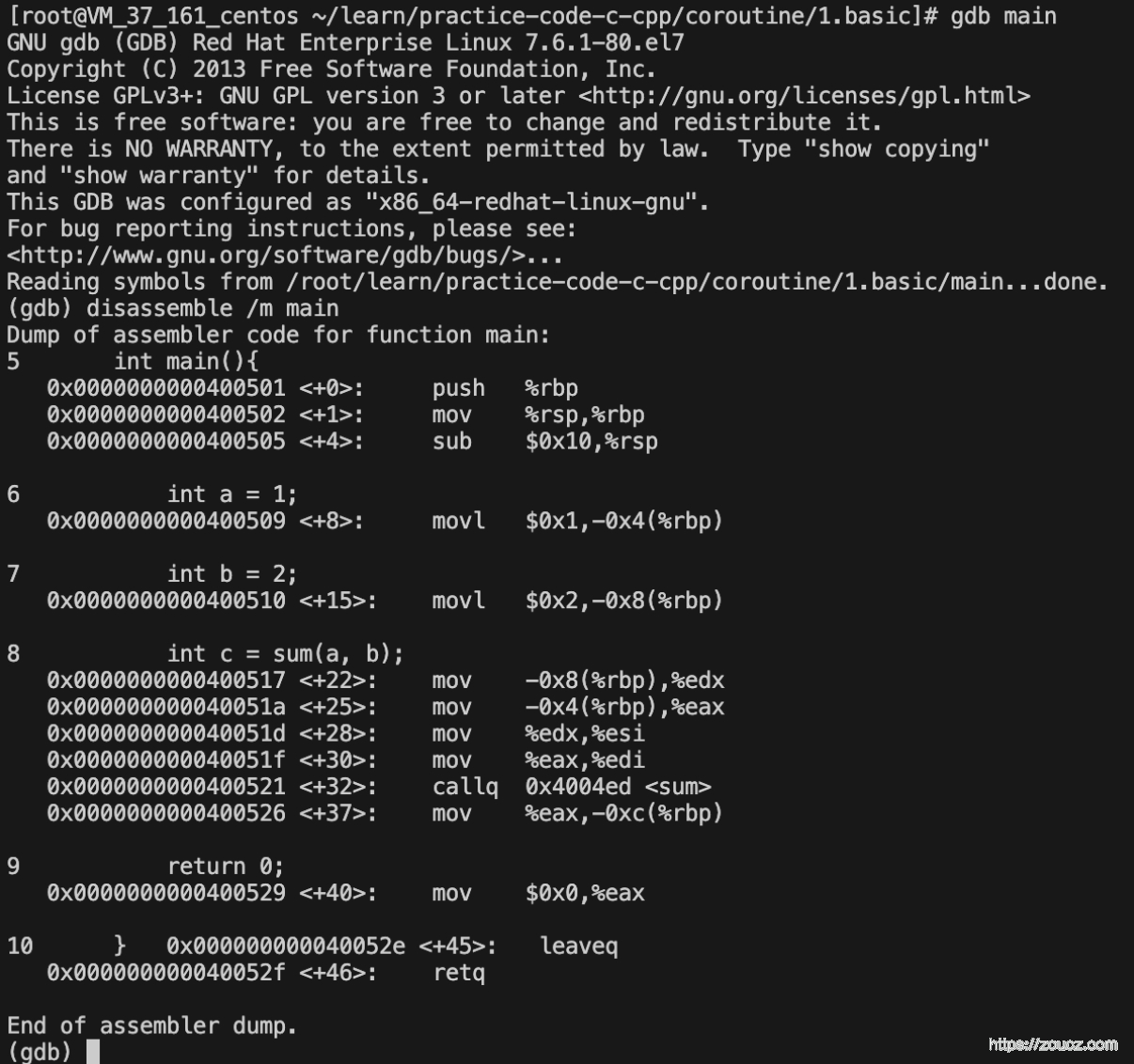
可以看到,main 函数的实际执行过程是1
5 int main(){
0x0000000000400501 <+0>: push %rbp # 将 %rbp 寄存器入栈,以保存之前的基地址
0x0000000000400502 <+1>: mov %rsp,%rbp # 将栈顶寄存器(%rsp)的值复制到基址寄存器(%rbp),创建新的栈帧
0x0000000000400505 <+4>: sub $0x10,%rsp # 将栈顶寄存器(%rsp)减 16,为局部变量预留空间
6 int a = 1;
0x0000000000400509 <+8>: movl $0x1,-0x4(%rbp) # 将值 1 存入基址寄存器(%rbp)减 4 的位置,即变量 a 的内存位置
7 int b = 2;
0x0000000000400510 <+15>: movl $0x2,-0x8(%rbp) # 将值 2 存入基址寄存器(%rbp)减 8 的位置,即变量 b 的内存位置
8 int c = sum(a, b); # 下面的汇编即为一个函数的调用过程
0x0000000000400517 <+22>: mov -0x8(%rbp),%edx # 将变量 b 的值复制到数据寄存器(%edx)
0x000000000040051a <+25>: mov -0x4(%rbp),%eax # 将变量 a 的值复制到累加寄存器(%eax)
0x000000000040051d <+28>: mov %edx,%esi # 将数据寄存器(%edx)的值复制到源索引寄存器(%esi),作为 sum 函数的第二个参数
0x000000000040051f <+30>: mov %eax,%edi # 将累加寄存器(%eax)的值复制到目的索引寄存器(%edi),作为 sum 函数的第一个参数
0x0000000000400521 <+32>: callq 0x4004ed <sum> # 调用 sum 函数
0x0000000000400526 <+37>: mov %eax,-0xc(%rbp) # 将累加寄存器(%eax)的值,即 sum 函数的返回值,存入基址寄存器(%rbp)减 12 的位置,即变量 c 的内存位置
9 return 0;
0x0000000000400529 <+40>: mov $0x0,%eax # 将值 0 存入累加寄存器(%eax),作为 main 函数的返回值
10 } 0x000000000040052e <+45>: leaveq # 恢复旧的栈帧,等效于同时执行 "mov %rbp, %rsp" 和 "pop %rbp"
0x000000000040052f <+46>: retq # 返回到调用 main 函数的代码位置
Step2. 观察 sum 函数的汇编代码

1 | 1 int sum(int l, int r) { 0x00000000004004ed <+0>: push %rbp # 将 %rbp 寄存器入栈,以保存之前的基地址 0x00000000004004ee <+1>: mov %rsp,%rbp # 将栈顶寄存器(%rsp)的值复制到基址寄存器(%rbp),创建新的栈帧 0x00000000004004f1 <+4>: mov %edi,-0x4(%rbp) # 将第一个参数(%edi)的值存入基址寄存器(%rbp)减 4 的位置,即变量 l 的内存位置 0x00000000004004f4 <+7>: mov %esi,-0x8(%rbp) # 将第二个参数(%esi)的值存入基址寄存器(%rbp)减 8 的位置,即变量 r 的内存位置 2 return l+r; 0x00000000004004f7 <+10>: mov -0x8(%rbp),%eax # 将变量 r 的值复制到累加寄存器(%eax) 0x00000000004004fa <+13>: mov -0x4(%rbp),%edx # 将变量 l 的值复制到数据寄存器(%edx) 0x00000000004004fd <+16>: add %edx,%eax # 将数据寄存器(%edx)的值加到累加寄存器(%eax),结果存入 %eax,即函数返回值 3 } 0x00000000004004ff <+18>: pop %rbp # 从堆栈中弹出值到基址寄存器(%rbp),恢复之前的栈帧 0x0000000000400500 <+19>: retq # 返回到调用 sum 函数的代码位置 |
Step3. 在 main 函数入口打上断点,并开始运行观察栈帧区间

可以看到,%rbp 的地址是 0x7fffffffe0b0,%rsp 的地址是 0x7fffffffe0a0,%rsp 比 %rbp 低 16 位,符合在 step1 中看到的执行步骤

查看 main 函数执行时 %rbp 地址中的值,发现是 0,说明没有上一次调用函数的 %rbp 地址
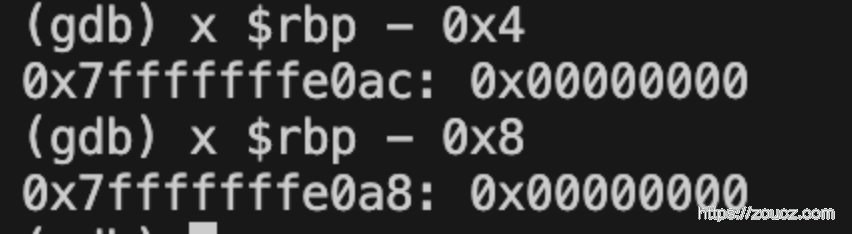
查看局部变量值,都是0
Step4. 在调用 sum 函数的地方打上断点,查看 main 函数栈帧区间的值和局部变量值
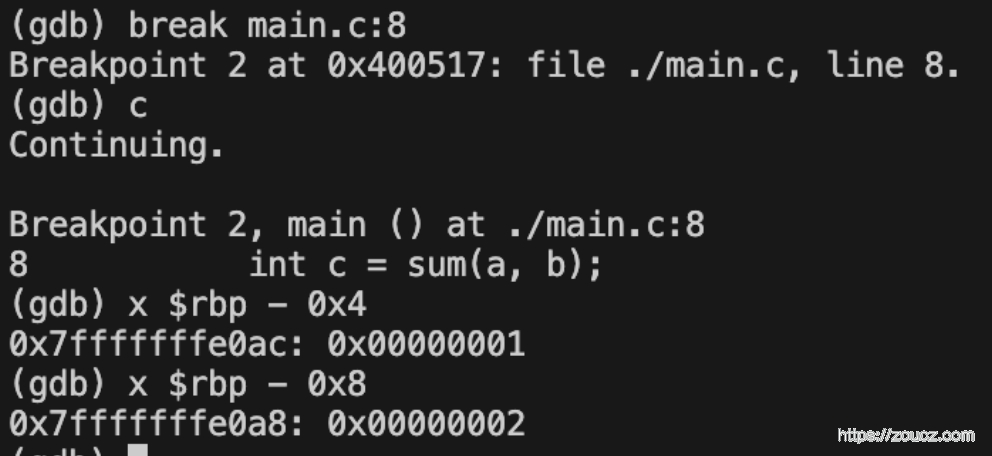
在第 8 行打上断点,继续执行,然后根据 %rbp 偏移定位得到局部变量 a、b 的地址,打印,发现已经有值了

栈帧区间不变
Step5. 在 sum 函数入口打上断点,查看 sum 函数的栈帧区间的值、返回地址、%rbp的值指向地址的值
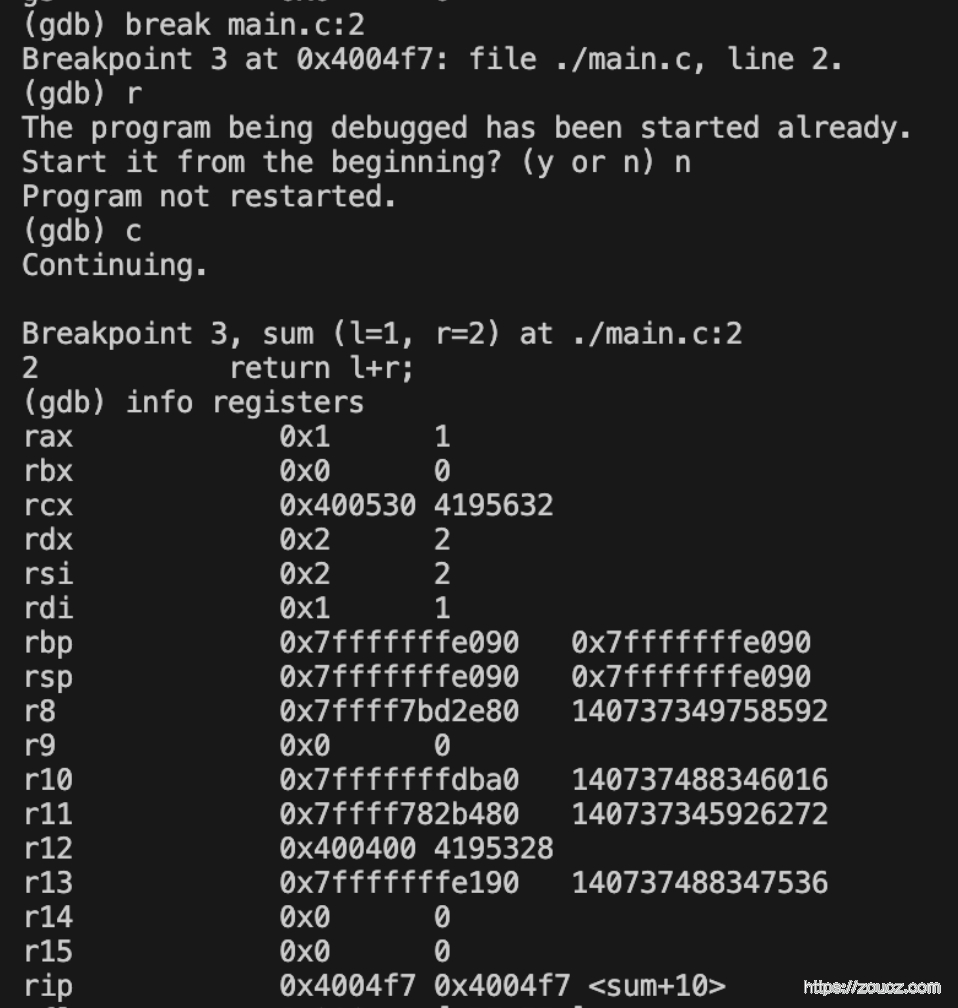
可以看到,%rbp 和 %rsp 的值发生了变化,且都是 0x7fffffffe090,因为 sum 函数没有局部变量,也不需要预留空间,符合在 Step2 中观察到的 sum 函数执行步骤。

查看 %rbp 指向的值,和 Step3 中 main 函数的栈帧 %rbp 指针地址一致,符合预期

根据 1.3 小节中的函数栈帧结构,我们知道 %rbp 地址向上偏移8个字节,就是函数的返回地址,打印出它的值,发现和 Step1 中 main 函数的返回地址能对上
1 | 0x0000000000400526 <+37>: mov %eax,-0xc(%rbp) |
Step6. 在 main 函数的结尾打上断点,查看 main 函数栈帧区间的值
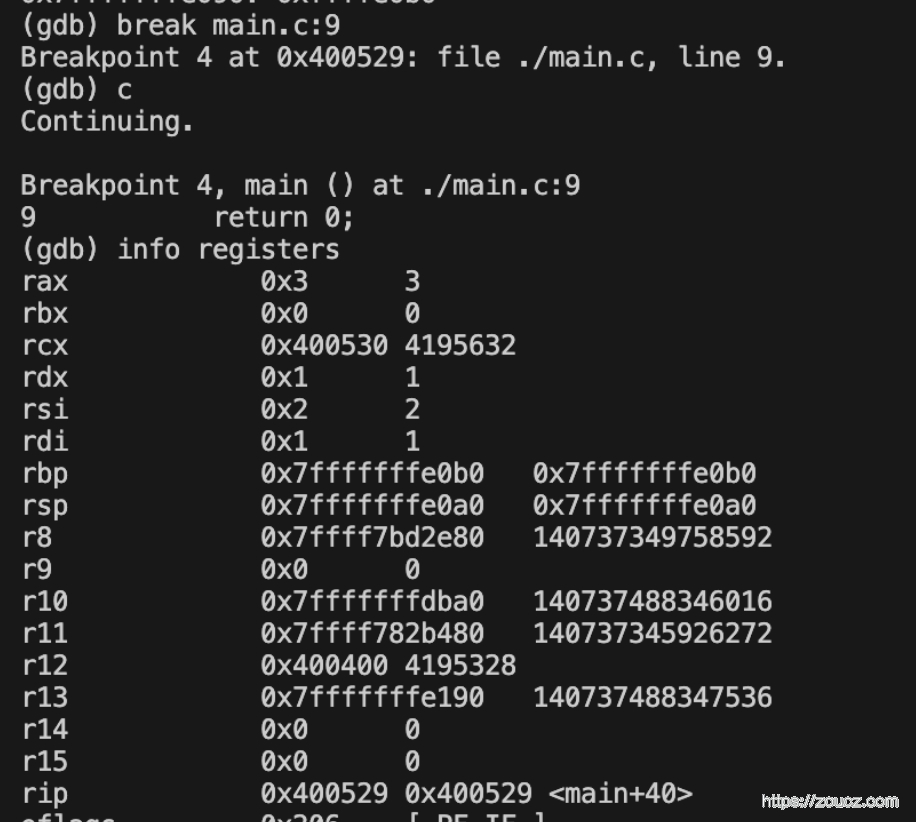
发现栈帧区间恢复到 main 函数的区间了,符合预期。
2. 有栈协程
当CPU执行任务时,切换线程需要执行保存当前线程的上下文(主要是寄存器)、加载新线程的上下文、更新线程控制块(Thread Control Block)、刷新内存管理单元(Memory Management Unit)等操作,而切换函数调用只需要执行一些栈帧的上下文切换工作。
函数调用的代价主要取决于参数的数量和大小以及栈操作的开销。相比之下,线程切换需要保存和恢复更多的寄存器,更新线程控制块和刷新内存管理单元等,这些操作会导致更高的延迟和资源消耗,通常会比函数执行的切换高出一个数量级。
有栈协程可以理解为一个用户态下的线程,在用户态下进行函数的上下文切换。和线程不同的是:线程是抢占式执行,当发生系统调用或者中断的时候,交由内核调度执行;而协程是通过 yield 在用户态主动让出 cpu 所有权,切换到其他协程执行。
2.1 极简有栈协程实现
c 标准库提供了一套方法用于操作用户态的上下文栈1
2
3
4
5
6#include <ucontext.h>
int getcontext(ucontext_t *ucp); // 获取
int setcontext(const ucontext_t *ucp); // 设置
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...); // 修改指向
int swapcontext(ucontext_t *restrict oucp,
const ucontext_t *restrict ucp); // 切换上下文
基于这些方法,我们可以实现一个极简版的协程示例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51#include <ucontext.h>
#include <stdio.h>
// 创建协程上下文
ucontext_t main_ctx, co1_ctx, co2_ctx;
// 创建协程栈
char co1_stack[1024*128], co2_stack[1024*128];
// 协程1:打印偶数
void co1() {
for (int i = 0; i < 10; i+=2) {
printf("co1: %d\n", i);
// 切换到协程2
swapcontext(&co1_ctx, &co2_ctx);
}
// 打印完偶数后切换回主协程
swapcontext(&co1_ctx, &main_ctx);
}
// 协程2:打印奇数
void co2() {
for (int i = 1; i < 10; i+=2) {
printf("co2: %d\n", i);
// 切换到协程1
swapcontext(&co2_ctx, &co1_ctx);
}
// 打印完奇数后切换回主协程
swapcontext(&co2_ctx, &main_ctx);
}
int main() {
// 初始化协程1上下文并切换到协程1
getcontext(&co1_ctx);
co1_ctx.uc_stack.ss_sp = co1_stack;
co1_ctx.uc_stack.ss_size = sizeof(co1_stack);
co1_ctx.uc_link = &main_ctx;
makecontext(&co1_ctx, co1, 0);
// 初始化协程2上下文并切换到协程2
getcontext(&co2_ctx);
co2_ctx.uc_stack.ss_sp = co2_stack;
co2_ctx.uc_stack.ss_size = sizeof(co2_stack);
co2_ctx.uc_link = &main_ctx;
makecontext(&co2_ctx, co2, 0);
printf("start coroutine\n");
swapcontext(&main_ctx, &co1_ctx);
printf("stop coroutine\n");
return 0;
}
执行结果:
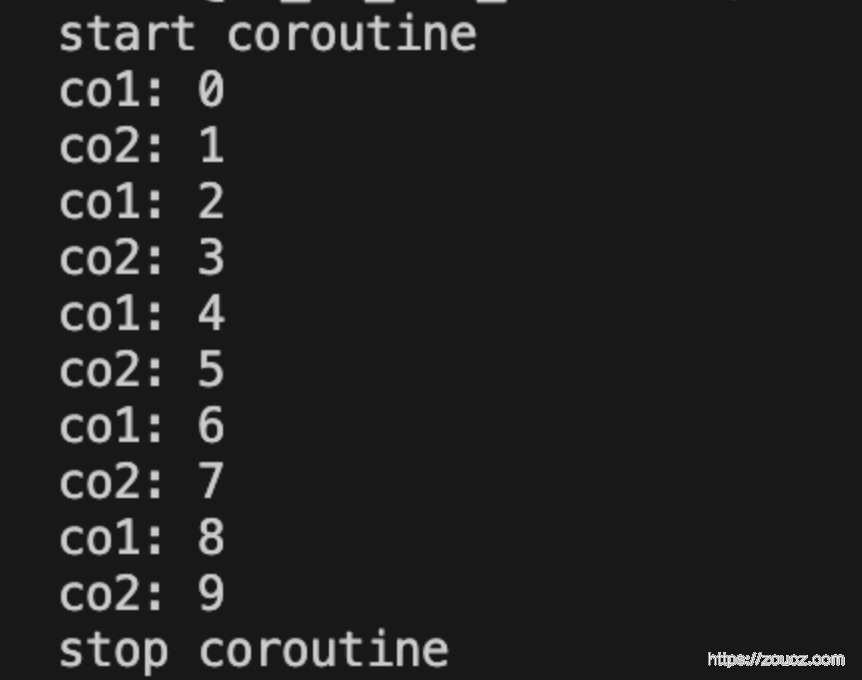
这样就实现了最简单的协程功能。
2.2 基于汇编有栈协程实现
这里给出一个最简单的基于汇编替代 ucontext 来实现协程功能的示例,无法真正用在项目中,但是可以演示出有栈协程的基本原理了。实际业界的 libco 等库也会自行基于汇编实现替代 ucontext 的部分功能,已获取更好的性能表现。
首先定义三个方法,用来保存、恢复、切换协程上下文 coctx_op.h1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24#ifndef _COCTX_OP_H
#define _COCTX_OP_H
// 定义各种字节大小的类型
typedef unsigned char byte1_t;
typedef unsigned short byte2_t;
typedef unsigned int byte4_t;
typedef unsigned long long byte8_t;
// 定义协程上下文结构体
typedef struct {
byte8_t retaddr; // 返回地址
byte8_t registers[7]; // 寄存器
byte4_t mxcsr; // 浮点状态寄存器
byte2_t x87cw; // 控制字
byte2_t padding; // 不使用,仅用于填充大小到8字节倍数
} coctx_t;
// 声明协程保存、恢复和切换函数
extern int coctx_save(coctx_t *old_ctx); // 保存协程上下文
extern int coctx_resume(coctx_t *new_ctx); // 恢复协程上下文
extern int coctx_swap(coctx_t *old_ctx, coctx_t *new_ctx); // 切换协程上下文
#endif /* coctx_op.h */
基于汇编实现上面的三个方法 coctx_op.S1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84#define _retaddr 0
#define _rsp 8
#define _rbp 16
#define _rbx 24
#define _r12 32
#define _r13 40
#define _r14 48
#define _r15 56
#define _mxcsr 64
#define _x87 68
.text // 指定代码段
.globl coctx_save // 定义全局符号 coctx_save
.type coctx_save, @function // 指定 coctx_save 类型为函数
coctx_save: // coctx_save 函数实现
// 保存返回地址
movq (%rsp), %r11
movq %r11, _retaddr(%rdi)
// 保存栈指针
leaq 8(%rsp), %r11
movq %r11, _rsp(%rdi)
// 保存寄存器
movq %rbp, _rbp(%rdi)
movq %rbx, _rbx(%rdi)
movq %r12, _r12(%rdi)
movq %r13, _r13(%rdi)
movq %r14, _r14(%rdi)
movq %r15, _r15(%rdi)
// 保存浮点状态
stmxcsr _mxcsr(%rdi)
fnstcw _x87(%rdi)
// 返回 0
movl $0, %eax
// 返回
retq
.size coctx_save, .-coctx_save
.globl coctx_resume // 定义全局符号 coctx_resume
.type coctx_resume, @function // 指定 coctx_resume 类型为函数
coctx_resume: // coctx_resume 函数实现
// 恢复栈指针和返回地址
movq _rsp(%rdi), %rsp
movq _retaddr(%rdi), %r11
pushq %r11
// 恢复寄存器
movq _rbp(%rdi), %rbp
movq _rbx(%rdi), %rbx
movq _r12(%rdi), %r12
movq _r13(%rdi), %r13
movq _r14(%rdi), %r14
movq _r15(%rdi), %r15
// 恢复浮点状态
ldmxcsr _mxcsr(%rdi)
fldcw _x87(%rdi)
// 返回 0
movl $0, %eax
// 返回
retq
.size coctx_resume, .-coctx_resume
.globl coctx_swap // 定义全局符号 coctx_swap
.type coctx_swap, @function // 指定 coctx_swap 类型为函数
coctx_swap: // coctx_swap 函数实现
// 保存返回地址、栈指针和寄存器
movq (%rsp), %r11
movq %r11, _retaddr(%rdi)
leaq 8(%rsp), %r11
movq %r11, _rsp(%rdi)
movq %rbp, _rbp(%rdi)
movq %rbx, _rbx(%rdi)
movq %r12, _r12(%rdi)
movq %r13, _r13(%rdi)
movq %r14, _r14(%rdi)
movq %r15, _r15(%rdi)
// 保存浮点状态
stmxcsr _mxcsr(%rdi)
fnstcw _x87(%rdi)
// 恢复栈指针、返回地址和寄存器
movq _rsp(%rsi), %rsp
movq _retaddr(%rsi), %r11
pushq %r11
movq _rbp(%rsi), %rbp
movq _rbx(%rsi), %rbx
movq _r12(%rsi), %r12
使用的示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43#include "coctx_op.h"
#include <stdio.h>
// 创建协程上下文
coctx_t main_ctx, co1_ctx, co2_ctx;
// 创建协程栈
char co1_stack[1024*128], co2_stack[1024*128];
// 协程1:打印偶数
void co1() {
for (int i = 0; i < 10; i+=2) {
printf("co1: %d\n", i);
// 切换到协程2
coctx_swap(&co1_ctx, &co2_ctx);
}
}
// 协程2:打印奇数
void co2() {
for (int i = 1; i < 10; i+=2) {
printf("co2: %d\n", i);
// 切换到协程1
coctx_swap(&co2_ctx, &co1_ctx);
}
}
int main() {
// 初始化协程1上下文并切换到协程1
co1_ctx.registers[0] = (byte8_t)(co1_stack + sizeof(co1_stack));
co1_ctx.retaddr = (byte8_t)co1;
// 初始化协程2上下文并切换到协程2
co2_ctx.registers[0] = (byte8_t)(co2_stack + sizeof(co2_stack));
co2_ctx.retaddr = (byte8_t)co2;
printf("start coroutine\n");
// 保存主协程上下文
coctx_save(&main_ctx);
// 启动协程
coctx_resume(&co1_ctx);
printf("stop coroutine\n");
// 切回主协程上下文
coctx_swap(&co1_ctx, &main_ctx);
return 0;
}
1 | cmake_minimum_required(VERSION 3.10) |
编译执行结果
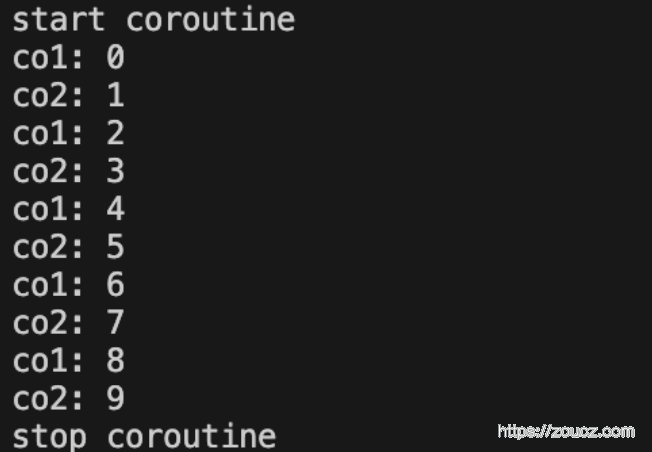
2.3 协程库实现
基于前面极简版的实现,我们可以稍微做一点封装,实现协程的调度器,以及创建、切换、恢复、销毁等方法。
coroutine.h1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62#include <stdio.h>
#include <ucontext.h>
#include <stdlib.h>
// 前向声明
typedef struct coroutine coroutine_t;
typedef struct scheduler scheduler_t;
// 协程结构体
struct coroutine {
ucontext_t ctx; // 协程上下文
void (*func)(void *); // 协程函数
void *arg; // 协程函数参数
int is_done; // 协程是否已完成
scheduler_t *sched; // 指向调度器的指针
};
// 调度器结构体
struct scheduler {
coroutine_t *current; // 当前运行的协程
ucontext_t main_ctx; // 主函数上下文,用于在协程间切换
};
// 创建协程
coroutine_t *coroutine_create(scheduler_t *sched, void (*func)(void *), void *arg) {
coroutine_t *co = (coroutine_t *)malloc(sizeof(coroutine_t));
getcontext(&co->ctx);
co->ctx.uc_stack.ss_sp = malloc(1024 * 1024); // 分配栈空间
co->ctx.uc_stack.ss_size = 1024 * 1024;
co->ctx.uc_link = &sched->main_ctx;
co->func = func;
co->arg = arg;
co->is_done = 0;
co->sched = sched;
makecontext(&co->ctx, (void (*)(void))func, 1, co);
return co;
}
// 销毁协程
void coroutine_destroy(coroutine_t *co) {
free(co->ctx.uc_stack.ss_sp);
free(co);
}
// 协程切换
void coroutine_yield(coroutine_t *co) {
if (co->sched->current != co) {
printf("Error: not the current coroutine.\n");
return;
}
swapcontext(&co->sched->current->ctx, &co->sched->main_ctx);
}
// 启动或恢复协程
void coroutine_resume(coroutine_t *co) {
if (co->is_done) {
printf("Coroutine is already done.\n");
return;
}
co->sched->current = co;
swapcontext(&co->sched->main_ctx, &co->ctx);
}
调用示例 main.c1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26#include "coroutine.h"
// 协程函数示例
void my_coroutine(void *arg) {
coroutine_t *co = (coroutine_t *)arg;
int *n = (int *)co->arg;
for (int i = 0; i < *n; i++) {
printf("Coroutine: %d\n", i);
coroutine_yield(co);
}
}
int main() {
scheduler_t sched = {0};
int n = 5;
coroutine_t *co1 = coroutine_create(&sched, my_coroutine, &n);
coroutine_t *co2 = coroutine_create(&sched, my_coroutine, &n);
for (int i = 0; i < n; i++) {
coroutine_resume(co1);
coroutine_resume(co2);
}
coroutine_destroy(co1);
coroutine_destroy(co2);
return 0;
}
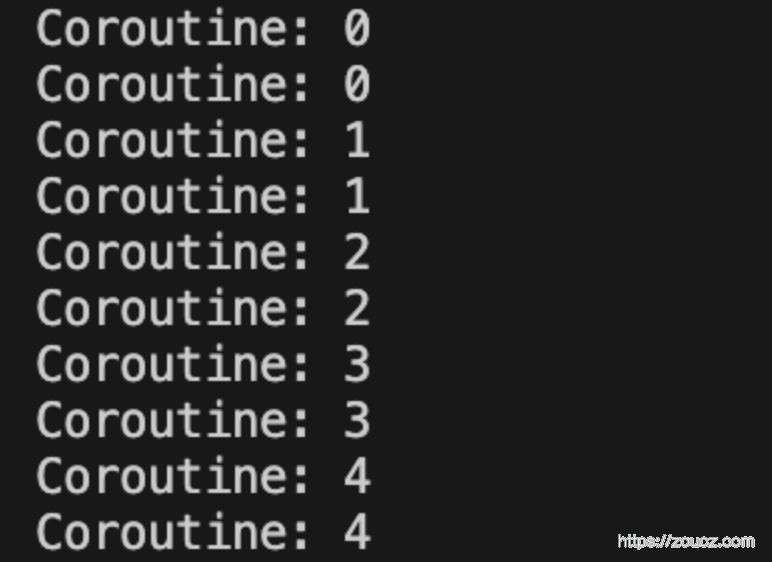
2.4 配合事件库/多路复用库实现同步语法
基于事件库或者 epoll 等多路复用库操作 IO 时,对于异步执行的结果,一般是通过回调函数来执行获取结果和后续操作
1 | #include <event2/event.h> |
回调函数的写法会使功能逻辑分散,且回调多了之后代码比较难维护。我们可以借助前面封装的协程库,配合事件库 / epoll 一起,实现一个协程 IO 调度功能,以同步的语法写 IO 结果获取和后续操作。
1 | #include <event2/event.h> |
实际上 libco 内部也实现了类似的机制,不过 libco 中是基于 epoll 自行封装的事件模块。
2.5 常见的 c++ 协程库
C++ 协程库有以下几个常见的库,它们的实现方案也有所不同:
- Boost.Coroutine2:Boost.Coroutine2 是 Boost C++ 库中的一个协程库。它基于底层的上下文切换库 Boost.Context 实现,提供了协程的创建、切换和销毁等功能。Boost.Coroutine2 使用栈式协程,可以在函数调用过程中进行协程切换。它的接口设计和实现都遵循了 C++ 标准中的协程规范。
- Libaco:Libaco 是一个轻量级的 C++ 协程库,它基于汇编实现了协程的上下文切换。Libaco 支持多种平台,并提供了简洁的 API。它使用共享栈式协程,可以在多个协程之间共享栈空间,从而减少内存开销。
- Libtask:Libtask 是一个基于 C 语言实现的协程库,但可以在 C++ 项目中使用。它基于 setjmp/longjmp 实现了协程的上下文切换,并提供了协程调度器和同步原语等功能。Libtask 使用栈式协程,支持协程之间的同步和通信。
- Gorilla:Gorilla 是一个基于 C++11 实现的协程库,它使用 ucontext API 实现了协程的上下文切换。Gorilla 提供了基于事件的异步 I/O 模型,支持协程之间的同步和通信。它使用栈式协程,支持多个协程并发执行。
- Protothreads:Protothreads 是一个非常轻量级的协程库,它基于 C 语言宏实现了协程的创建和切换。Protothreads 使用线程式协程,通过编译器技巧将协程切换嵌入到函数调用过程中。Protothreads 适用于资源受限的嵌入式系统。
这些协程库的实现方案主要有以下几种:
- 基于底层上下文切换库(如 Boost.Context)实现。
- 基于汇编实现协程的上下文切换。
- 基于 setjmp/longjmp 实现协程的上下文切换。
- 基于 ucontext API 实现协程的上下文切换。
- 基于编译器技巧(如 C 语言宏)实现协程的创建和切换。
3. 无栈协程
3.1 和有栈协程的区别
无栈协程和有栈协程的主要区别在于它们在协程切换时是否需要保存和恢复栈上下文。
无栈协程:
- 定义:无栈协程是一种不依赖于栈进行上下文切换的协程实现方式。在无栈协程中,协程之间的切换不会涉及到栈的保存和恢复,而是通过其他方式(如闭包、编译器技巧、内部数据结构等)来保留协程的状态和局部变量。
- 内存开销:由于无栈协程不使用栈进行切换,因此每个协程的内存开销较小。这使得无栈协程在资源受限的环境中,如嵌入式系统,具有较好的适应性。
- 切换开销:无栈协程的上下文切换不涉及栈的保存和恢复,因此切换开销相对较低。这使得无栈协程在需要频繁切换的场景下具有较好的性能。
- 编程模型:由于无栈协程的实现通常需要使用编译器技巧,如 C 语言宏或特殊的控制结构,因此无栈协程的使用和编程模型相对复杂。这可能导致无栈协程在实际开发中的应用受到限制。
有栈协程:
- 定义:有栈协程是一种依赖于栈进行上下文切换的协程实现方式。在有栈协程中,协程之间的切换涉及到栈的保存和恢复。每个协程都有自己独立的栈空间,用于保存局部变量和执行状态。
- 内存开销:由于有栈协程使用栈进行切换,因此每个协程的内存开销较大。这使得有栈协程在资源受限的环境中可能不太适用。
- 切换开销:有栈协程的上下文切换涉及栈的保存和恢复,因此切换开销相对较高。这使得有栈协程在需要频繁切换的场景下可能性能较差。
- 编程模型:有栈协程的编程模型相对简单,它允许在协程中直接使用函数调用、循环和其他控制结构,而无需使用复杂的回调函数或特殊语法。这使得有栈协程在实际开发中的应用更加广泛。
3.2 常见的无栈协程
以下是一些常见的无栈协程及其实现方案:
- Protothreads:Protothreads 是一个非常轻量级的协程库,主要用于资源受限的嵌入式系统。Protothreads 使用 C 语言宏实现协程的创建和切换,它通过将协程的状态保存在局部变量中,而不是在栈中,从而实现无栈协程。
- Lua 协程:Lua 语言中的协程是无栈协程,它通过将协程的状态保存在 Lua 虚拟机的内部数据结构中,而不是在栈中,从而实现无栈协程。Lua 协程提供了 yield 和 resume 函数,用于在协程之间进行切换。
- JavaScript 的 async/await:JavaScript 的 async/await 是一种特殊的无栈协程。它通过 Promise 对象和事件循环机制,实现了在异步操作中使用同步编程风格的能力。在 async/await 中,协程的状态被保存在 Promise 对象和闭包中,而不是在栈中。
- C# 的 async/await:C# 的 async/await 也是一种特殊的无栈协程。它通过 Task 对象和编译器转换,实现了在异步操作中使用同步编程风格的能力。在 C# 的 async/await 中,协程的状态被保存在 Task 对象和编译器生成的状态机中,而不是在栈中。
- Python 的 asyncio:Python 的 asyncio 库提供了一种基于事件循环的无栈协程。在 asyncio 中,协程是通过生成器函数实现的,协程的状态被保存在生成器对象中,而不是在栈中。asyncio 提供了 yield from 和 await 语法,用于在协程之间进行切换。
- C++20 的协程:在 C++20 的协程中,协程的状态和局部变量可以被存储在堆上分配的内存中,从而减少栈的使用。这种优化取决于编译器和协程库的实现。C++20 提供了 co_await,co_yield 和 co_return 等关键字,用于创建和控制协程。
这些无栈协程的实现方案主要有以下几种:
- 使用编译器技巧,如 C 语言宏或特殊的控制结构,实现协程的创建和切换。
- 将协程的状态保存在内部数据结构或对象中,如 Lua 虚拟机的内部数据结构,Promise 对象,Task 对象,生成器对象等。
- 使用事件循环和回调机制,实现协程的调度和切换。
参考文档:
- 《程序员的自我修养》
- https://yangsoon.github.io/有栈协程实现原理
- https://zhuanlan.zhihu.com/p/347445164 有栈协程和无栈协程
- https://cloud.tencent.com/developer/article/1888257
本文链接:https://www.zoucz.com/blog/2023/04/09/2b247f70-d6aa-11ed-9fa0-5dbc93f9d3ee/
